地图开发科普篇:如何利用大数据技术处理海量GPS数据
2017年09月20日 作者:
我秀中国物联网地图服务平台目前接入的监控车辆近百万辆,每天采集GPS数据7亿多条,产生日志文件70GB,使用传统的数据处理方式非常耗时。
比如,仅仅对GPS做一些简单的统计分析,程序就需要几个小时才能跑完一天的数据,完全达不到实时分析的要求,更无法对数据进行一些深层次的挖掘。
另外历史数据的存储也是一个亟待解决的问题,目前大多采用的方式是将日志文件进行压缩后上传到服务器上进行存储。
这种方式既原始又不可靠,一是需要作业员每天定时手动上传数据,操作不方便;二是一旦存储数据的服务器出现问题,可能会造成大量数据的丢失,造成不可挽回的损失。
随着大数据技术的成熟和普及,我们发现借助于大数据技术可以完美的解决上述问题。根据目前的需求和对大数据相关软件的掌握,我们对GPS日志分析系统做了初步的设计,架构如下图所示:
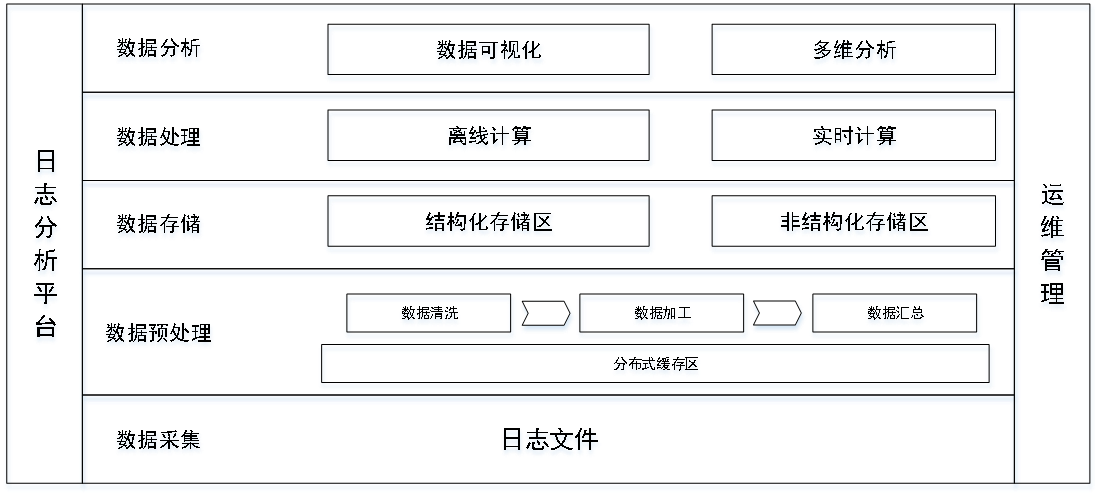
大数据日志分析主要是对开源大数据组件进行整合开发而成,分为:数据采集层、数据预处理层、数据存储层、数据处理层和数据分析层等5个层次。
01、数据采集层
数据采集层主要利用开源组件Flume对日志文件进行采集。Flume是一个分布式、高可靠、高可用的海量日志采集软件,支持定制各类的数据发送方,在收集数据的同时能够对数据进行简单的处理,然后写到各种数据接收方。
目前我们是对Flume采集的日志文件做两个操作,一是直接发送给kafka进行缓存,二是将数据进行压缩后写入HDFS供之后的分析用。
02、数据预处理
数据预处理主要对日志文件进行初步的简单处理。目前采用Storm从Kafka接收数据,然后对数据进行实时统计。
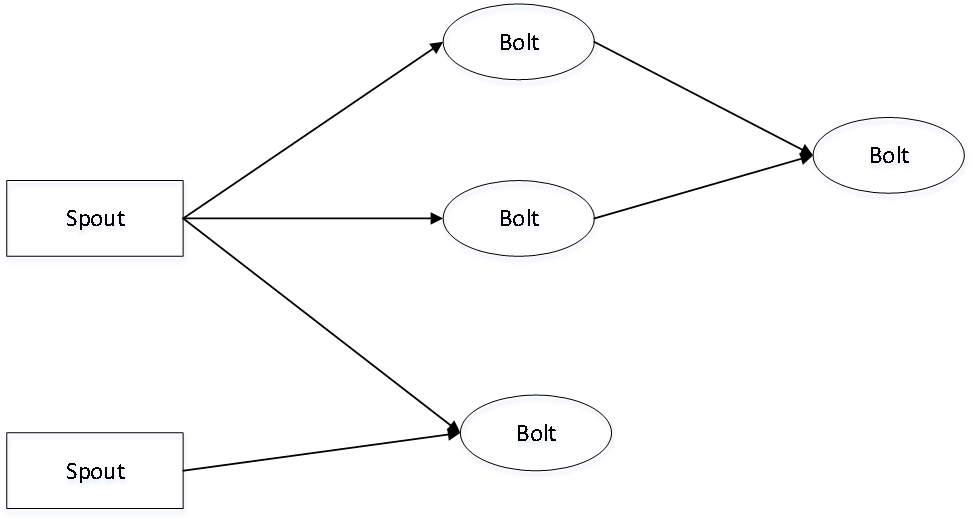
Storm是一个分布式、容错的实时计算系统。它的编程模型非常简洁,主要包括三个组件:Topology、Spout和Bolt。Topology是一个由多个计算节点构成的拓扑图,Spout和Bolt是两种结算节点,它们一起构成了一个完整的数据流向图。
03、数据存储层
数据存储层主要用于数据的存储。目前采用MongoDB存储结果数。
通过Storm处理后的数据,首先缓存到Redis中,每隔一定得时间间隔,将数据批量转存到MongoDB中。
MongoDB是一个高性能、易部署、易使用的分布式数据存储系统,介于结构化数据库和非结构化数据库之间,数据存储格式不固定,可以非常方便的进行扩充。
04、数据处理层
数据处理层主要采集一些数据挖掘算法对数据进行挖掘,或者进行实时计算。
数据挖掘主要借助于统计学方法、机器学习方法、神经网络方法等对数据进行知识挖掘,发掘潜在的价值。
比如利用线性回归算法,预测车辆的停留时间。利用k-means算法对位置临近的出租车做聚类分析,从而发现最有可能搭载乘客的热点区域。根据速度将轨迹数据进行分段,从而分析某个时间段的道路畅通状况等。
05、数据分析层
数据分析层主要是数据的展示和分析。
比如将GPS数据加载到地图上,利用抓路算法将GPS数据和地图数据进行融合,对分段的轨迹进行不同颜色的显示,可以让调度人员对当前时间段的道路通行情况一目了然,辅助车辆的调度。
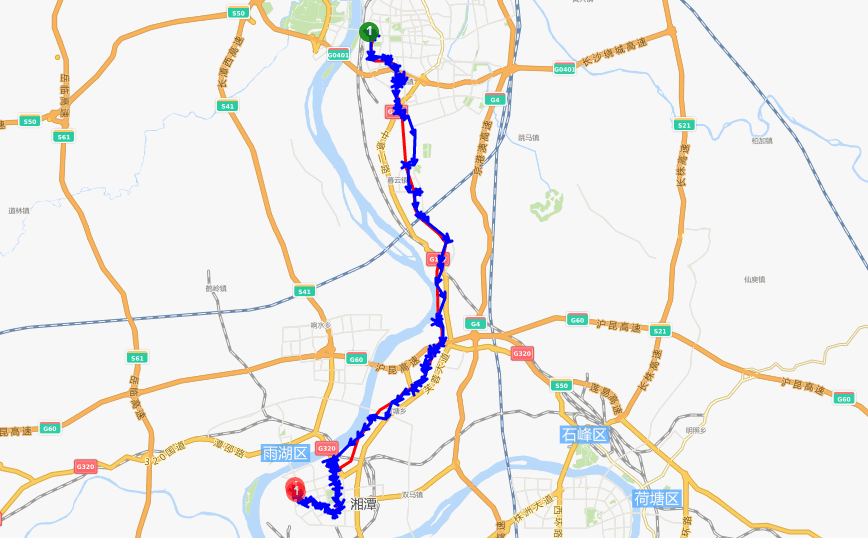
我们不断提高自身数据处理能力,就是为了给您提供更快速、更精准、更丰富的数据分析功能。

 15201338330(同微信)
15201338330(同微信) 127817479
127817479

